AIGC applications represented by ChatGPT have brought great changes to enterprise production and greatly improved people's production efficiency. Large AI models can help to complete various complex tasks, such as helping developers write, debug and record codes, researchers quickly understand scientific research fields, marketers write product descriptions, etc. More and more enterprises have begun to attach importance to AIGC application development. How to manage the API of large AI models through the gateway has become a concern.
Higress is a next-generation cloud-native gateway based on Alibaba's internal gateway practices. Powered by Istio and Envoy, Higress realizes the integration of the triple gateway architecture of traffic gateway, microservice gateway, and security gateway, thereby greatly reducing the costs of deployment, operation, and maintenance. Based on the rich capabilities provided by Higress, enterprises can greatly reduce the cost of using large AI models.
How does Higress reduce the cost of using AI models?
Taking OpenAI as an example, OpenAI's APIs are priced not based on the number of requests or subscription time but based on the usage of each request. For large AI models, tokens are the standard billing strategy for OpenAI API as a measure of the complexity of inference tasks. The cost for tokens varies based on the model. Generally, more complex models give better results at a higher cost. API Keys are distributed to consumers for authentication and charging.

It is unrealistic for an organization to apply for an API Key for each member. Scattered API keys will not be conducive to the organization's calculation, management, and payment of API usage, thereby increasing the cost of using large AI models. For organizations, the selection and access rights of AI models, the frequency of use of AI models and access permissions, and the management and protection of data exposed to AI models are all important API management.
Based on rich plugin capabilities, Higress provides functions such as authentication, request filtering, traffic control, usage monitoring, and security protection, helping organizations interact with large AI model APIs more securely, reliably, and observably. Based on the authentication provided by Higress, organizations can implement multi-tenant authentication and grant different AI model access rights to team members; based on the traffic control capability, organizations can set differentiated access rate limits for different models and users, effectively reducing the cost of using AI model; based on the request interception capability, organizations can effectively filter access requests containing sensitive information, and protect some internal site resources from being exposed to the outside world, effectively ensuring data security. Based on the index query and log system capabilities provided by Commercial Higress, organizations can observe and analyze the usage of AI model calls by different users to formulate more reasonable AI model usage strategies.

Manage OpenAI API with Higress
We will take Higress connecting to the OpenAI API as an example to introduce how Higress seamlessly connects to the large AI model. The overall solution is shown in Fig.3. We have extended the Higress plugin based on WASM to proxy requests to the OpenAI language model. Based on authentication plugins such as Key Auth, we implement multi-tenant authentication under a unified OpenAI API-Key. Based on the Request-Block plugin, we implement the interception of requests with sensitive information and ensure data protection.
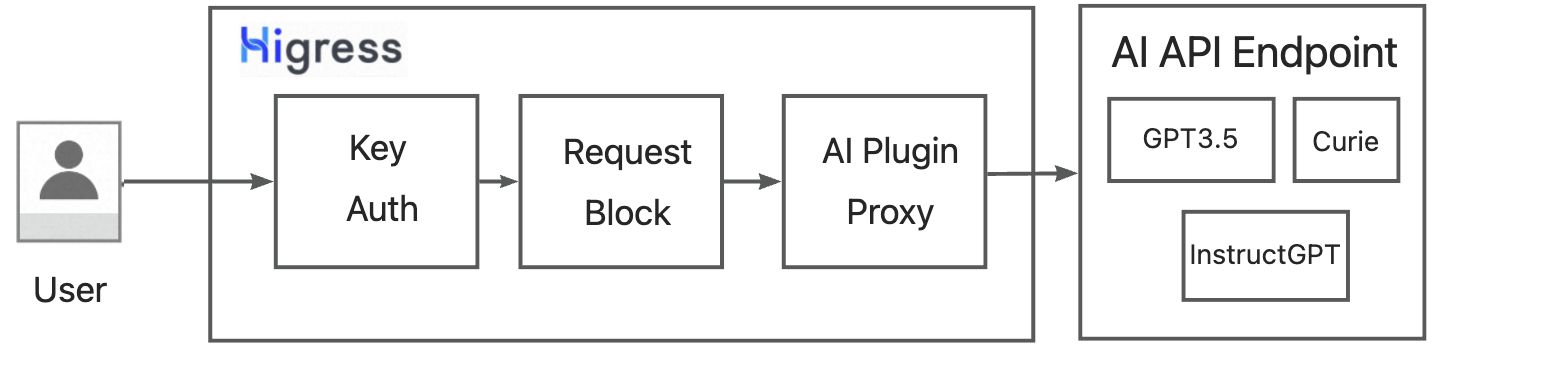
Prerequisites
- Install Higress. Please refer to Deploy Higress by Helm.
- Prepare the development environment for WASM plugins with Golang. Please refer to Developing a WASM plugin with Golang | Higress.
AI Proxy WASM Plugin
The following will give the AI proxy plugin implementation based on Higress and WASM. Higress supports scalability externally based on WASM. The multi-language ecology and hot-swapping mechanism provided by the WASM facilitate the implementation and deployment of the plugin. Higress also supports requesting external services in the plugin, which provides an efficient solution path for the implementation of the AI proxy plugin.
Code Implementation
The following code implements the request proxy to OPENAI-API based on HTTP. For details, please refer to the AI proxy plugin. The specific implementation steps are as follows:
- Create a new HTTP client, specify the OpenAI API host through the RouteCluster method, and determine the request proxy path.
func parseConfig(json gjson.Result, config *MyConfig, log wrapper.Log) error {
//The default forwarding path is OpenAI API.
//Users can adjust through configuration.
chatgptUri := json.Get("chatgptUri").String()
var chatgptHost string
if chatgptUri == "" {
config.ChatgptPath = "/v1/completions"
chatgptHost = "api.openai.com"
}
...
//Specify the specific request proxy host through RouteCluster.
config.client = wrapper.NewClusterClient(wrapper.RouteCluster{
Host: chatgptHost,
})
...
}
- Encapsulate the request in the OpenAI-API format, send requests and receive responses through the HTTP Client, and send responses to the user.
//OPENAI API request body template. Please refer to https://platform.openai.com/docs/api-reference/chat
const bodyTemplate string = `
{
"model":"%s",
"prompt":"%s",
"temperature":0.9,
"max_tokens": 150,
"top_p": 1,
"frequency_penalty": 0.0,
"presence_penalty": 0.6,
"stop": ["%s", "%s"]
}
`
func onHttpRequestHeaders(ctx wrapper.HttpContext, config MyConfig, log wrapper.Log) types.Action {
...
//Encapsulate the OPENAI API request body according to the user's request content.
body := fmt.Sprintf(bodyTemplate, config.Model, prompt[0], config.HumanId, config.AIId)
//Post request via HTTP client.
err = config.client.Post(config.ChatgptPath, [][2]string{
{"Content-Type", "application/json"},
{"Authorization", "Bearer " + config.ApiKey},
}, []byte(body),
func(statusCode int, responseHeaders http.Header, responseBody []byte) {
var headers [][2]string
for key, value := range responseHeaders {
headers = append(headers, [2]string{key, value[0]})
}
//Receive the response from the OPENAI API and send it to user
proxywasm.SendHttpResponse(uint32(statusCode), headers, responseBody, -1)
}, 10000)
...
}
Enable the custom AI-Proxy-Wasm plugin in Higress as follows:

This example provides the compiled AI-proxy-plugin WASM file and completes the construction and push of the docker image. The recommended configuration is as follows:
| Name | Recommended configuration |
|---|---|
| Image URL | oci://registry.cn-hangzhou.aliyuncs.com/zwj_test/chatgpt-proxy:1.0.0 |
| Plugin Execution Phase | Authz |
| Plugin Execution Priority | 1 |
Plugin configuration instructions
AI-Proxy-Plugin is easy to configure and supports proxy forwarding at the global/domain name level/routing level. Route-level configuration is recommended: route config-strategy-enable plugin. An example configuration is as follows:
apiKey: "xxxxxxxxxxxxxxxxxx"
model: "curie"
promptParam: "text"
According to this configuration, the gateway proxies to the Curie model in OpenAI, and the user enters prompts in the URL through the keyword "text".
curl "http://{GatewayIP}/?text=Say,hello"
Response from Curie model in OpenAI:

Multi-tenant authentication based on Key Auth
Different from the form of issuing AI-API keys for each member, enterprises can utilize internal authorization (such as Key Auth, etc.) and rely on the unified AI-API key for request proxy to achieve unified management of API usage.
Key Auth implements the authentication based on the Gateway level API Key. Key Auth supports parsing the API Key from the URL parameter or request header of the HTTP requests and verifies whether the API has permission to access.
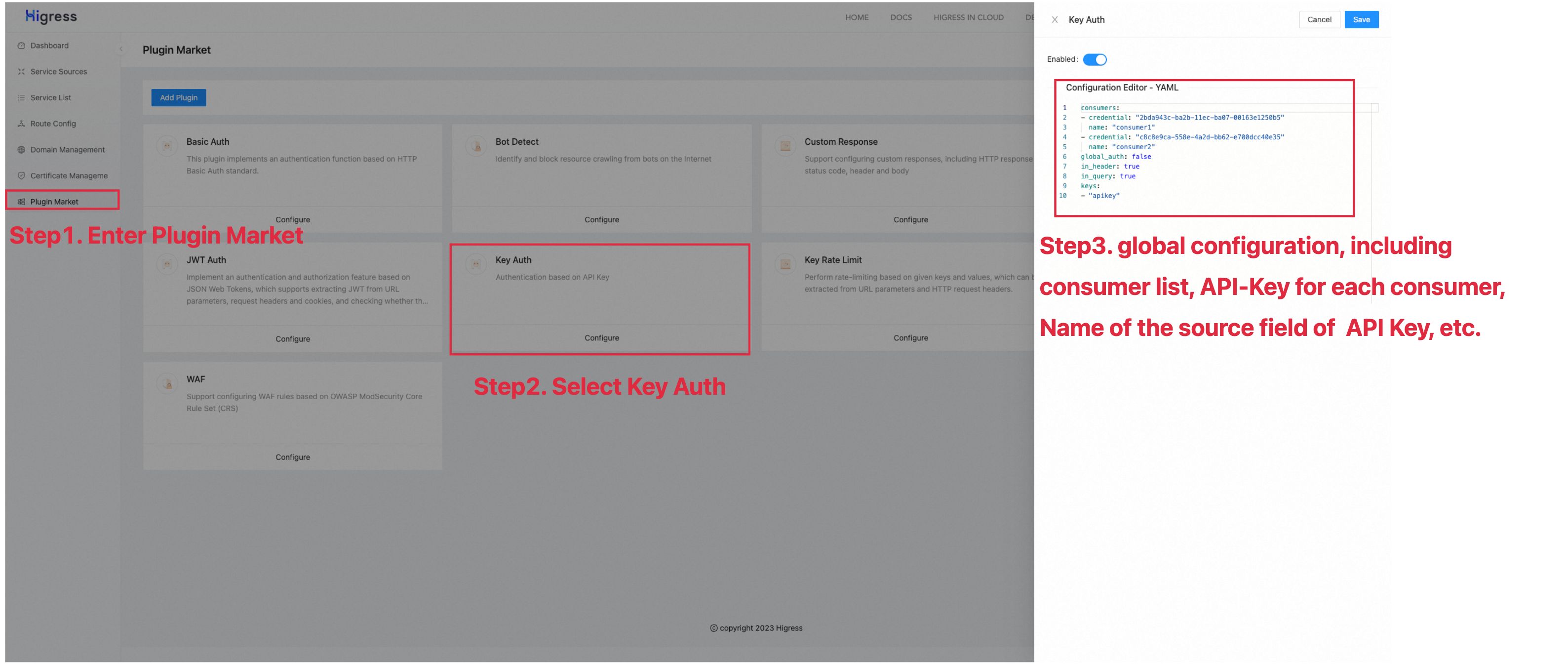
consumers:
- credential: "xxxxxx"
name: "consumer1"
- credential: "yyyyyy"
name: "consumer2"
global_auth: false
in_header: true
keys:
- "apikey"
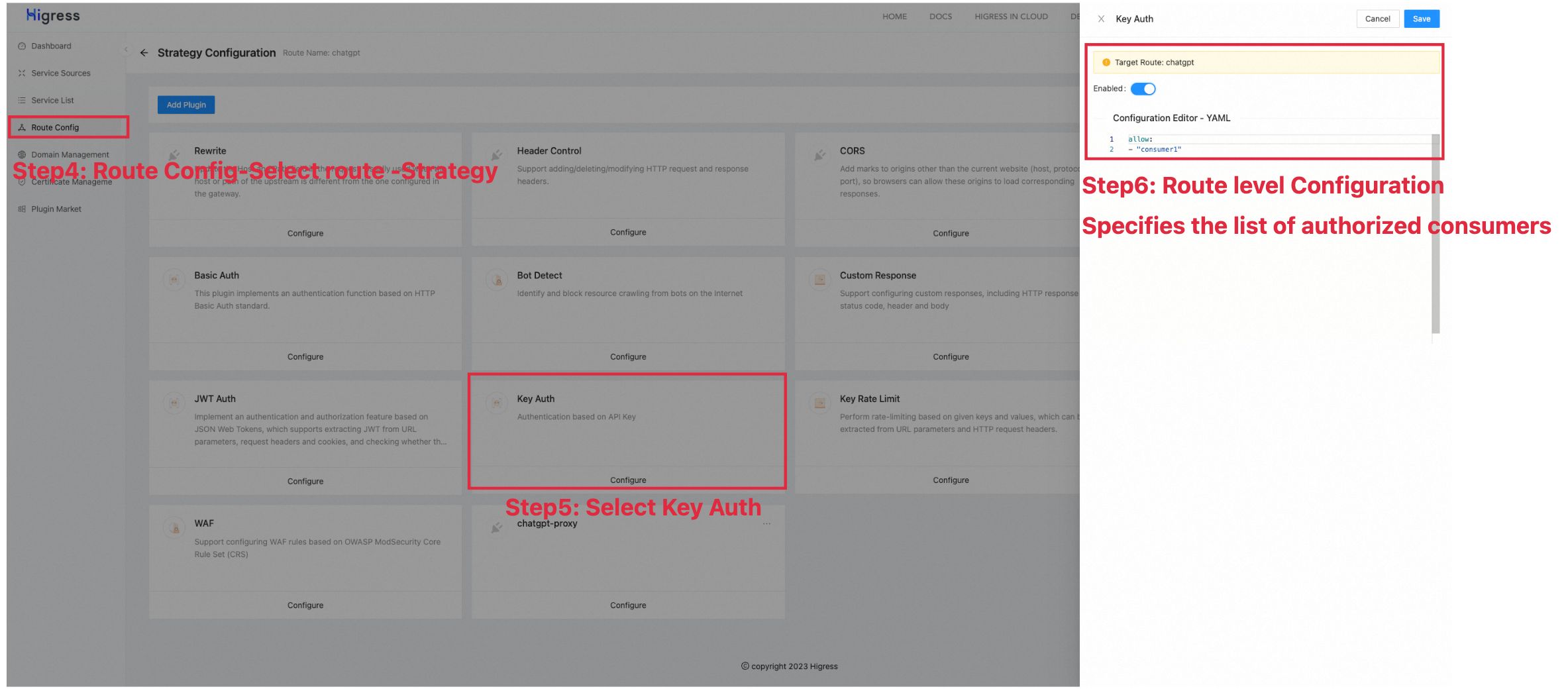
allow: [consumer1]
The above configuration defines consumers, and only consumer1 has the access right to the AI model service under the current route.
curl "http://{GatewayIP}/?text=Say,hello"
#The request does not provide an API Key, return 401
curl "http://{GatewayIP}/?text=Say,hello" -H "apikey:zzzzzz"
#The API Key provided by the request is not authorized to access, return 401
curl "http://{GatewayIP}/?text=Say,hello" -H "apikey:yyyyyy"
#The caller matched according to the API Key provided in the request has no access rights, return 403
curl "http://{GatewayIP}/?text=Say,hello" -H "apikey:xxxxxx"
#The caller has access to the AI model service, the request will be proxied to the AI model, and the response from the OpenAI API will be received normally
In addition to providing gateway-level multi-tenant authentication, Higress provides traffic control and other capabilities. The Key Rate Limit plugin can limit the user's application rate based on the user's membership in the consumption group.
Data protection based on Request Block
For AIGC applications, especially LLM services, a good return often requires users to provide enough prompts as model input. Users face the risk of data leakage in the process of providing prompts. Ensuring data security in the process of using the AIGC application is also an important issue for API callers.
Protecting data security involves stringent control over the API calling channels. One method involves confirming specifically approved models with their published API. Another way is to intercept user requests containing sensitive information. These can be achieved by setting specific request interception at the gateway level. Higress provides request interception based on the request block plugin, which can prevent unauthorized models from accessing user information and prevent user requests containing sensitive information from being exposed to the external network.
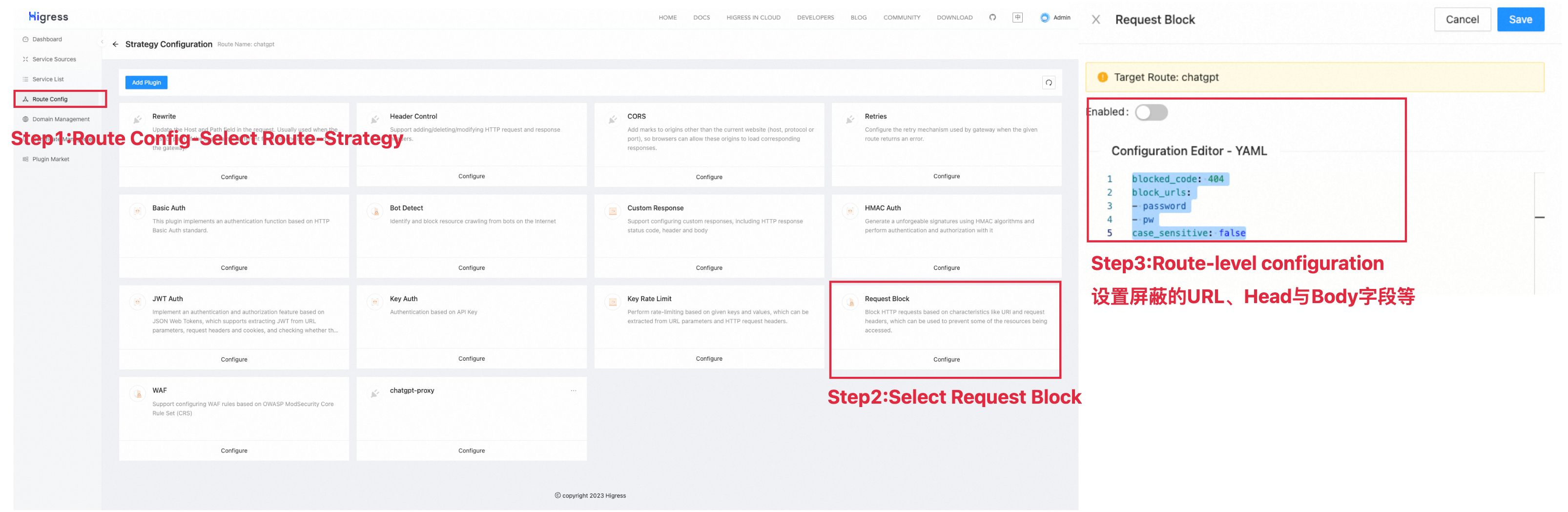
blocked_code: 404
block_urls:
- password
- pw
case_sensitive: false
The above configuration defines URL-based shielding fields under the current route, in which requests containing sensitive information such as "password" and "pw" will be blocked。
curl "http://{GatewayIP}/?text=Mypassword=xxxxxx" -H "apikey:xxxxxx"
curl "http://{GatewayIP}/?text=pw=xxxxxx" -H "apikey:xxxxxx"
#The above request will be forbidden and return 404
Usage observation and analysis
For organizations, observing and analyzing the usage of large AI model calls for each user helps to understand their usage and costs. It is also necessary for individual users to understand their own call volume and overhead. Commercial Higress is deeply integrated with various metrics and log systems and provides an out-of-the-box usage observation and analysis report construction mechanism, which can view the usage of various APIs in real time and filter according to various parameters.
Taking the observation of each user's usage of the OPENAI-Curie model as an example, the administrator can set the observability parameter in the request header:x-mse-consumer, to distinguish users through MSE console - Cloud native Gateway - Gateway instance - Parameter Configurator- Custom Format. After adding the observability parameters, enter the Observation Analysis - Log Center to set the use statistics chart function to complete the observation and analysis of API usage. As shown in the figure below, the amount of calls to the OPENAI-Curie model of user consumer1 and user consumer2 is presented in the form of a pie chart.

Join the Higress community
Join Higress Slack: https://join.slack.com/t/w1689142780-euk177225/shared_invite/zt-1zbjm9d34-4nptVXPpNvnuKEKZ7V3MIg
To get invited: https://communityinviter.com/apps/w1689142780-euk177225/higress
If you find Higress helpful, welcome to Higress to star us!